NLP و کامپیوتر بصری یکپارچه
NLP و کامپیوتر بصری یکپارچه

ادغام و بین رشته ای سنگ بنای علم و صنعت مدرن هستند. یکی از نمونه های تلاش های اخیر برای ترکیب همه چیز ، ادغام بینایی رایانه و پردازش زبان طبیعی (NLP) است. هر دوی این زمینه ها یکی از فعال ترین مناطق تحقیقاتی یادگیری ماشین هستند. با این حال ، تا همین اواخر ، آنها به عنوان مناطق جداگانه بدون راههای زیادی برای بهره مندی از یکدیگر رفتار می شدند. در حال حاضر ، با گسترش چند رسانه ای ، محققان بررسی امکان استفاده از هر دو رویکرد برای دستیابی به یک نتیجه را آغاز کرده اند. استخراج و تجزیه و تحلیل اطلاعات از منابع مختلف. این مطابق با نظریه نشانه شناسی است (گرینلی 1978) - مطالعه روابط بین علائم و معانی آنها در سطوح مختلف. نشانه شناسی رابطه بین علائم و معنا ، روابط رسمی بین نشانه ها (تقریباً معادل نحو) و نحوه تفسیر علائم توسط افراد بسته به زمینه (عملگرایی در نظریه زبانی) را مطالعه می کند. اگر نشانه های کاملاً بصری را در نظر بگیریم ، این نتیجه می شود که می توان با دید رایانه ای به نشانه شناسی نیز نزدیک شد و علائم جالبی را برای پردازش زبان طبیعی استخراج کرد تا معانی متناظر را متوجه شود.
بینایی رایانه ای و ارتباط آن با NLP
مالک وظایف Computer Vision را در 3R خلاصه می کند (Malik و همکاران 2016): بازسازی ، تشخیص و سازماندهی مجدد.
بازسازی به برآورد یک صحنه سه بعدی اشاره دارد که باعث ایجاد یک تصویر بصری خاص شده است. با ترکیب اطلاعات از نماهای متعدد ، سایه ، بافت یا حسگرهای عمق مستقیم. این فرایند به یک مدل سه بعدی مانند ابرهای نقطه ای یا تصاویر عمیق منجر می شود.
تشخیص شامل اختصاص برچسب به اشیاء در تصویر است. برای اشیاء دو بعدی ، نمونه های تشخیص عبارتند از دست خط یا تشخیص چهره ، و کارهای سه بعدی با مشکلاتی مانند تشخیص اشیا از ابرهای نقطه ای که به دستکاری روباتیک کمک می کند ، برخورد می کنند.
سازماندهی مجدد به معنای بینایی از پایین به بالا است ، زمانی که پیکسل های خام به بخش هایی تقسیم می شوند. گروه هایی که نمایانگر ساختار یک تصویر هستند. وظایف بینایی سطح پایین شامل تشخیص لبه ، خطوط و گوشه است ، در حالی که وظایف سطح بالا شامل تقسیم بندی معنایی است که تا حدی با وظایف تشخیص همپوشانی دارد.
این شناخت بیشترین ارتباط را با زبان دارد زیرا دارای خروجی است که می تواند به عنوان کلمات تفسیر شود. به عنوان مثال ، اشیاء را می توان با اسم ، فعالیتها را بر فعلها و ویژگیهای شی را با صفات نشان داد. از این نظر ، بینایی و زبان با استفاده از بازنمایی های معنایی به هم متصل می شوند (Gardenfors 2014 ؛ Gupta 2009). در مقایسه با بینایی رایانه ای و از نحو ، شامل ریخت شناسی و ترکیب بندی ، معناشناسی به عنوان مطالعه معنا ، شامل روابط بین کلمات ، عبارات ، جملات و گفتمان ها ، تا عمل گرایی ، مطالعه سایه های معنا ، در سطح ارتباط طبیعی است.
برخی از کارهای پیچیده در NLP شامل ترجمه ماشینی ، رابط گفتگو ، استخراج اطلاعات و خلاصه سازی است.
اعتقاد بر این است که تغییر تصویر از کلمات نزدیکترین به ترجمه ماشینی است. با این حال ، چنین "ترجمه" بین پیکسل های سطح پایین یا خطوط تصویر و توصیف سطح بالا در کلمات یا جملات-وظیفه ای که به عنوان پل شکاف معنایی شناخته می شود (ژائو و گروسکی 2002)-یک شکاف گسترده برایمتقاطع.
حوزه ادغام بینایی رایانه ای و NLP
ادغام بینایی و زبان به صورت عمدی از بالا به پایین بدون مشکل انجام نمی شد ، جایی که محققان مجموعه ای از اصول. تکنیک های یکپارچه از پایین به بالا توسعه یافتند ، زیرا برخی از پیشگامان مشکلات مشخص و باریک را شناسایی کردند ، چندین راه حل را امتحان کردند و نتیجه رضایت بخشی یافتند.
مسیر جدید با درک این نکته که اکثر فایل های امروزی چند رسانه ای ، که شامل تصاویر ، فیلم ها و متون به زبان طبیعی است. برای مثال ، یک مقاله خبری معمولی حاوی نوشته ای توسط یک روزنامه نگار و عکس مربوط به محتوای خبری است. علاوه بر این ، ممکن است یک ویدئوی کلیپی وجود داشته باشد که حاوی یک گزارشگر یا تصویر لحظه ای از صحنه ای باشد که رویداد در خبر رخ داده است. داده های زبانی و تصویری دو مجموعه اطلاعات را ارائه می دهد که در یک داستان واحد ترکیب شده و زمینه را برای ارتباط مناسب و بدون ابهام فراهم می کند. در کار با فایل های چند رسانه ای ، بلکه در زمینه های رباتیک ، ترجمه های بصری و معانی توزیعی.
فایل های چند رسانه ای
وظایف مربوط به چند رسانه ای برای NLP و بینایی رایانه ای در سه بخش اصلی قرار می گیرد. دسته ها: توصیف خواص بصری ، توصیف بصری و بازیابی بصری.
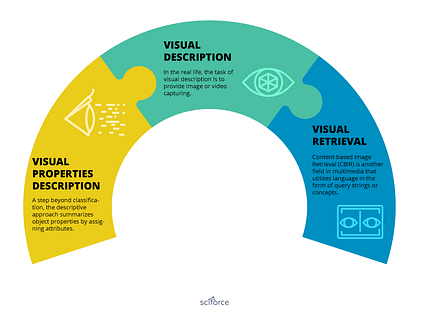 < p> توصیف ویژگیهای بصری: یک مرحله فراتر از طبقه بندی ، رویکرد توصیفی با اختصاص ویژگیها ، ویژگیهای شی را خلاصه می کند. چنین ویژگیهایی ممکن است هم ارزشهای دوتایی برای خواصی باشند که به راحتی قابل تشخیص هستند و هم ویژگیهای نسبی که با کمک یک چارچوب یادگیری-رتبه بندی یک ویژگی را توصیف می کنند. نکته اصلی این است که ویژگی ها مجموعه ای از زمینه ها را به عنوان منبع دانش برای تشخیص یک شیء خاص با ویژگی های آن ارائه می دهند. کلمات ویژگی به نمایشی متوسط تبدیل می شوند که به پل شکاف معنایی بین فضای بصری و فضای برچسب کمک می کند.
< p> توصیف ویژگیهای بصری: یک مرحله فراتر از طبقه بندی ، رویکرد توصیفی با اختصاص ویژگیها ، ویژگیهای شی را خلاصه می کند. چنین ویژگیهایی ممکن است هم ارزشهای دوتایی برای خواصی باشند که به راحتی قابل تشخیص هستند و هم ویژگیهای نسبی که با کمک یک چارچوب یادگیری-رتبه بندی یک ویژگی را توصیف می کنند. نکته اصلی این است که ویژگی ها مجموعه ای از زمینه ها را به عنوان منبع دانش برای تشخیص یک شیء خاص با ویژگی های آن ارائه می دهند. کلمات ویژگی به نمایشی متوسط تبدیل می شوند که به پل شکاف معنایی بین فضای بصری و فضای برچسب کمک می کند. توصیف بصری: در زندگی واقعی ، وظیفه توصیف بصری ارائه تصویر یا ویدئو است. اعتقاد بر این است که جملات توصیف آموزنده تری از یک تصویر ارائه می دهند تا یک کلمه از کلمات بی نظم. برای ایجاد جمله ای که یک تصویر را توصیف می کند ، باید مقدار مشخصی از اطلاعات بصری سطح پایین را استخراج کرد که اطلاعات اساسی "چه کسی با چه کسی و کجا و چگونه آن را انجام داد" را ارائه می دهد. از دیدگاه بخشی از گفتار ، چهارقلوهای "اسم ها ، افعال ، صحنه ها ، حروف اضافه" می توانند نشان دهنده معنی استخراج شده از آشکارسازهای بصری باشند. ماژول های بصری اشیائی را استخراج می کنند که در جمله یا فاعل یا شیء هستند. سپس از یک مدل مارکوف پنهان برای رمزگشایی محتمل ترین جمله از مجموعه ای از چهارقلوهای نامحدود به همراه تعدادی از پیشگامان راهنمای پیکر برای پیش بینی فعل و صحنه (حرف اضافه) استفاده می شود. این معنا با استفاده از اشیاء (اسم) ، ویژگی های بصری (صفت) و روابط فضایی (حروف اضافه) نشان داده می شود. سپس این جمله با استفاده از تکنیک ترکیب ترکیب با استفاده از n-gram در مقیاس وب برای تعیین احتمالات تولید می شود.
بازیابی بصری: بازیابی تصویر مبتنی بر محتوا (CBIR) یکی دیگر از زمینه های چند رسانه ای است که از زبان استفاده می کند. در قالب رشته ها یا مفاهیم پرس و جو. به عنوان یک قاعده ، تصاویر با ویژگی های سطح پایین مانند رنگ ، شکل و بافت نمایه می شوند. سیستم های CBIR سعی می کنند یک ناحیه تصویر را با a حاشیه نویسی کنندکلمه ، شبیه به تقسیم بندی معنایی ، بنابراین برچسب های کلیدواژه به تفسیر انسان نزدیک است. سیستم های CBIR از کلمات کلیدی برای توصیف یک تصویر برای بازیابی تصویر استفاده می کنند ، اما ویژگی های بصری یک تصویر را برای درک تصویر توصیف می کنند. با این وجود ، ویژگی های بصری یک لایه میانی مناسب برای CBIR با تطبیق با حوزه موردنظر فراهم می کند.
رباتیک
روباتیک بینایی: روبات ها باید محیط خود را از بیش از یک روش تعامل درک کنند به همانند انسان هایی که با استفاده از دانش خود در مورد اشیاء در قالب کلمات ، عبارات و جملات ، ورودی های ادراکی را پردازش می کنند ، روبات ها نیز باید تصور خود را با زبان ادغام کنند تا اطلاعات مربوط به اشیاء ، صحنه ها ، اقدامات یا رویدادهای موجود در آن را بدست آورند. دنیای واقعی ، آنها را درک کرده و اقدام مربوطه را انجام دهید. به عنوان مثال ، اگر یک شیء دور باشد ، یک اپراتور انسانی ممکن است به صورت شفاهی اقدامی را برای رسیدن به دیدگاه روشن تر درخواست کند. وظایف Robotics Vision مربوط به این است که چگونه یک روبات می تواند با استفاده از حسگرهای سخت افزاری مانند دوربین عمق یا دوربین حرکتی ، دنباله هایی از اقدامات را روی اشیا انجام دهد تا محیط واقعی را دستکاری کند.
< p> زبان موقعیتی: روباتها برای توصیف جهان فیزیکی و درک محیط خود از زبانها استفاده می کنند. علاوه بر این ، زبان گفتاری و حرکات طبیعی راه راحت تری برای تعامل با یک روبات برای انسان است ، در صورتی که روبات برای درک این شیوه تعامل آموزش دیده باشد. از دیدگاه انسان ، این روش تعامل طبیعی تر است. بنابراین ، یک روبات باید بتواند اطلاعات را از درک متنی خود با استفاده از ساختارهای معنایی درک و تبدیل کند. معروف ترین رویکرد برای بازنمایی معنا تجزیه معنایی است که کلمات را به محمولات منطقی تبدیل می کند. SP سعی می کند یک جمله زبان طبیعی را به نمایش معنای متناظر که می تواند یک شکل منطقی مانند λ-calculus با استفاده از گرامر طبقه بندی ترکیبی (CCG) به عنوان قواعدی برای ساخت ترکیبی درخت تجزیه باشد ، ترسیم کند.معناشناسی توزیعی
مدلهای معناشناسی توزیع چندوجهی اولیه: ایده ای که در مدلهای معناشناسی توزیعی وجود دارد این است که کلمات در زمینه های مشابه باید دارای معنای مشابه باشند ، بنابراین ، معنی کلمه را می توان از آمار همزمان بین کلمات و زمینه هایی که در آنها ظاهر می شود ، بازیابی کرد. اعتقاد بر این است که این روش در بینایی رایانه و پردازش زبان طبیعی به عنوان جاسازی تصویر و جاسازی کلمه مفید است. DSM ها برای مدل سازی معنایی مشترک بر اساس هر دو ویژگی بصری مانند رنگ ، شکل یا بافت و ویژگی های متنی مانند کلمات استفاده می شوند. خط متداول این است که داده های بصری را روی کلمات ترسیم کرده و مدلهای معناشناسی توزیعی مانند LSA یا مدلهای موضوعی را در بالای آنها اعمال کنید. ویژگیهای بصری می توانند ویژگیهای زبانی مدل معناشناسی توزیعی را تقریبی کنند.
مدلهای معناشناسی توزیع چندوجهی عصبی: مدلهای عصبی با یادگیری توزیع بهتر داده ها از بسیاری از روشهای سنتی در بینایی و زبانی پیشی گرفته اند. به عنوان مثال ، ماشینهای Multimodal Deep Boltzmann می توانند ویژگیهای بصری و متنی مشترک را بهتر از مدلهای موضوعی مدل کنند. علاوه بر این ، مدل های عصبی می توانند برخی از پدیده های قابل قبول شناختی مانند توجه و حافظه را الگو قرار دهند. برای توجه ، یک تصویر در ابتدا می تواند با استفاده از CNN وRNN ها یک شبکه LSTM را می توان در بالای صفحه قرار داد و مانند یک ماشین حالت دهنده عمل کرد که همزمان خروجی هایی تولید می کند ، مانند زیرنویس های تصویر یا به طور همزمان به مناطق مورد علاقه در یک تصویر نگاه می کند. برای حافظه ، دانش عمومی در پاسخ به س visualالات بصری
آینده ادغام NLP و بینایی رایانه
در صورت ترکیب ، دو وظیفه می تواند تعدادی از مشکلات طولانی مدت را در زمینه های مختلف حل کند ، از جمله:
با این حال ، از آنجا که ادغام بینایی و زبان یک مشکل اساسی شناختی است ، تحقیقات در این زمینه باید علوم شناختی را در نظر بگیرد که ممکن است بینش هایی را در مورد نحوه پردازش انسان ها به صورت کلی محتوای بصری و متنی و ایجاد داستان ارائه دهد. بر اساس آن.
منابع:
گوردنفورس ، ص. 2014. هندسه معنا: معناشناسی بر اساس فضاهای مفهومی. مطبوعات MIT.
گرینلی ، دی . 1978. نشانه شناسی و معنی. Int گل میخ فلسفه 10 (1978) ، 251-254.
گوپتا ، A. 2009. فراتر از اسمها و افعال. (2009).
مالک ، J. ، Arbeláez ، P. ، Carreira، J.، Fragkiadaki، K.، Girshick، R.، Gkioxari، G.، Gupta، S.، Hariharan، B. ، Kar ، A. و Tulsiani ، S. 2016. سه Rs بینایی رایانه ای: بازشناسی ، بازسازی و سازماندهی مجدد. تشخیص الگو.
شوکلا ، دی ، دسای A.A. یکپارچه سازی بینایی رایانه ای و پردازش زبان طبیعی: مسائل و چالش ها. مجله علم و فناوری VNSGU جلد. 4 ، №1 ، ص. 190–196.
Wiriyathammabhum، P.، Stay، D.S.، Fermüller C.، Aloimonos، Y. Computer Computer and Processing Natural Language Processing: Recent Approaches in Multimedia and Robotics. نظرسنجی های محاسباتی ACM 49 (4): 1–44